![]()
48 kHz/sec or 96 kHz/sec Sampling Frequency? During a visit to the USA, a listening session was organized to demonstrate the superiority of digital processing, operating at 96 kHz 24 bits over 48 kHz 24 bits. In order to do this, the organizers had adequate microphones, high quality 24 bit 96 kHz A/D and D/A converters, a recorder capable of recording this data rate and a listening system capable of showing the desired results. They had also made a series of recordings of various different musical styles in parallel at 24/96 kHz and 24/48 kHz. After the listening session, the participants' comments were very commendable. "We really heard a difference; the 24/96 kHz was much better!" Convinced by the reality of these comments, we, the Research and Development department set about to find a reasonable scientific hypothesis with which to explain that energy contained in a spectrum, outside which our ear, or more precisely, our hearing system can discern, improves the listening comfort of the music. The facts
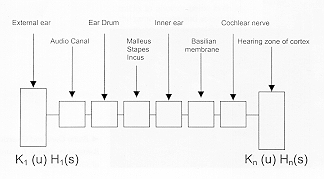
At a certain point in this chain, the acoustic signal is converted to an electrical signal. That task is assumed by the basilial membrane and is then sent via the Cochlea nerve to the brain. The factor Kn(u) placed in front of each module corresponds to the non-linear characteristics of each. In simpler terms, we can say that a variation by a factor of 2 of an input stimulus will have a variation factor of maybe 2.1 on the output signal and the signal will be deformed.
Now, what would happen if TWO sinusoidal signals of slightly different frequencies arrived concurrently at the input to the module? If our two signals correspond to the following formula: Then the resulting sum of the two superimposed signals would
be: Thus Uin1=sin
omega1t+sin omega2t
1=sin
omega1t+sin omega2t
and on the output of the module we would have: Or making the evaluation squared we get If we concentrate on the middle term which can be transformed
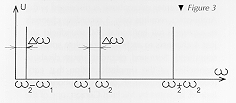
according to trigonometry such that: If we represent this middle operand in a spectral form, we would have
The interesting thing to be noted is found at the bottom-end of the spectrum, where the frequency corresponds to omega2-omega1 the unexpected component appears (Figure 3). In fact, if one of the modules at the beginning of the chain of Figure 1 presents the characteristics which we have just discussed, we could find, for example the following situation: If two frequencies, one of 30 kHz and the other of 31 kHz, both totally inaudible, stimulate the input of our module, we would see a frequency of 31 kHz-30 kHz = 1 kHz appears on the output, which in itself is perfectly audible. This is no great discovery. This principle has been known for years, in fact it is the principle of operation of all radio receivers. And it is also the source of the French "Luxembourg effect".
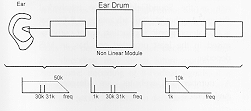
It is this behavior of our sense of hearing, which could explain, among other things, the surprise of the participants during the listening sessions mentioned at the beginning. Frequencies above 20 kHz, actually reproduced by a system operating at a sampling frequency of 96 kHz arrive in our hearing and interact with each other according to the demonstration above. The audio spectrum modified in this way could improve our perception of the sound. Is all this theory reasonable? We have decided to undertake a few different experiences to confirm or reject this. The first manipulation which came to mind, was to simply mix two high quality signal generators, amplify the signal and then play the results through a tweeter capable of restitution of a signal up to 35 kHz. Already excited with a modest level (about 2 Watts), with the ear placed at a distance of about 1 meter from the tweeter, we can in fact discern a frequency of 1 kHz quite clearly (31 kHz-30 kHz mentioned previously). At this point of the experiment, have we proved the presence, in our hearing, a system as described in Figure 4?
The two generators, independent from one another, as well as the mixer (two metal film Ľ W resistances) can in theory be eliminated as culprits. The amplifier, of excellent quality, (because we designed it!) is unlikely to create the effect discussed. Is it therefore the tweeter that is the weak element in the chain? To clarify this doubt, let's modify the experiment, and instead of feeding a tweeter with the two signals, let's feed the two signals (30 and 31 kHz) to individual tweeters. To push the test to extremes, we will also use two MPA amplifiers, one for each channel rather than a single stereo amplifier to avoid any interference at this point. Under this new configuration, even pushing the level to the limit accepted by the tweeters, the ear cannot distinguish any audible frequency at all (1 kHz), unlike before. It therefore seems that this phenomena does not occur within the human ear, but instead in the tweeter and the non-linearity's of the different elements therein (magnet, magnetic circuit, membrane, etc.). Even the air could have been the source of the problem. Effectively at high acoustic pressure levels above 130 dB SPL the air is non-linear and does present the characteristic. K=A2X˛ (In fact it is simple to understand, under compression, air can be compressed to more than 100 kg per cm˛ before it becomes a liquid. However, in diminishing the pressure, we cannot hope to go below absolute emptiness (-1kg per cm˛). This is the principle used in generation of ultra fine beams of infra-sounds - but this is a whole different story). Provisional conclusion Other phenomena concerning the behavior of the human hearing system can be demonstrated using short impulse sounds, but this will be the subject of the next chapter of the article!
NAGRA NEWS |
![]()
Back to Articles |Back to Homepage
![]()
![]() e-mail: pvm@stardustfilm.com
e-mail: pvm@stardustfilm.com ![]()
![]()
![]() 7510
SUNSET BLVD.
7510
SUNSET BLVD. ![]() PMB 240
PMB 240 ![]()
![]() HOLLYWOOD
HOLLYWOOD ![]() CALIFORNIA 90046
CALIFORNIA 90046 ![]() USA
USA ![]()
![]() TELEPHONE: (310)
288-7889
TELEPHONE: (310)
288-7889 ![]() FAX: (818) 763-5886
FAX: (818) 763-5886 ![]()
![]() www.stardustfilm.com
www.stardustfilm.com ![]()